预测性负载均衡
Steve Gury 的“预测性负载均衡:不公平但更快、更健壮”
客户端负载均衡方法
- 许多可用的服务器,选择哪一个
随机选择
- 随机选择服务器
- 随着(永远)时间的推移,所有服务器收到相同数量的请求
- 在短期内,真的可以给出不平衡的选择
轮询调度
- 客户端记住前一个服务器
- 选择列表中的下一个
最小负载
- 客户端跟踪每个服务器上的未完成请求
- 选择未完成请求数量最少的服务器
- [这听起来像是本地负载最少,客户端不知道服务器上的全局负载]
负载均衡问题
服务器并不完全相同
- 有些服务器可能更隐蔽
- 轮训调度将请求到这些服务器上,使许多请求非常慢
- 主负载需求将更少
惊群效应
- 新的可用资源被请求轰炸
- 新可用的资源可能还没有准备好
- [似乎与 Wikipedia 对 Thudnering Herd Problem 的定义不太一样]
- 轮询和随机不会轰炸新可用的资源
- 主负载会被轰击
异常值
- 服务器可能会遇到问题
- 例如 GC 暂停,CPU 峰值阻止处理
- 轮询将继续打击这些暂时缓慢的服务器
- 最小负载可能会好一点
具有独立状态的多个客户端
- 假设没有协调的全局状态
- 每个客户端都有服务器负载的视图
- 最小负载和轮询可能会选择全局加载最少的服务器
所有这些方法都有问题

- [我认为不是针对最少负载提出的最佳观点]
基于延迟的负载平衡
使用观察到的延迟作为负载的度量
*负载 = Predicted_Latency * (#requests + 1)*
- 每个服务器都有一个归因于它的延迟
- 现在决定服务器取决于响应的预计到达时间
预测延迟
响应延迟直方图的中位数(不是平均值)
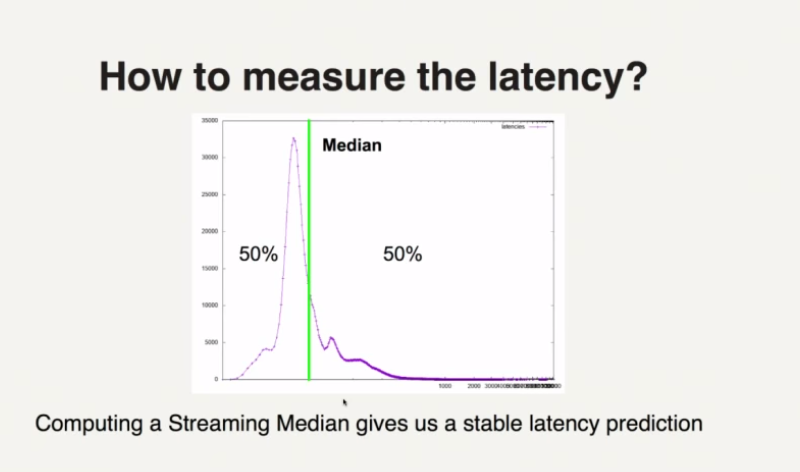
比平均水平更稳定
滑动窗口上的直方图以说明最近的服务器更改
当历史数据陈旧时,延迟会衰减(自行下降)
- 鼓励访问很久没见过的服务器,以防万一发生了变化
- 如果服务器仍然很慢,它会重新提高延迟(一段时间后会再次衰减)
问题和解决方案
- 如何估计新服务器(无历史数据)
- 解决方案:试用期预热服务器,建立历史
- 如果服务器返回错误但响应时间很快怎么办
- 解决方案:忽略错误延迟
- 解决方案:使用失败响应来处置延迟
快速响应延迟
跟踪尚未收到响应的请求
如果响应尚未到达预测的时间,我们可以立即调整开始调整预测负载并继续调整它
如果需要调度其他请求,可以使用调整后的预测负载做出决定(在响应返回之前,或者发生大超时之前)
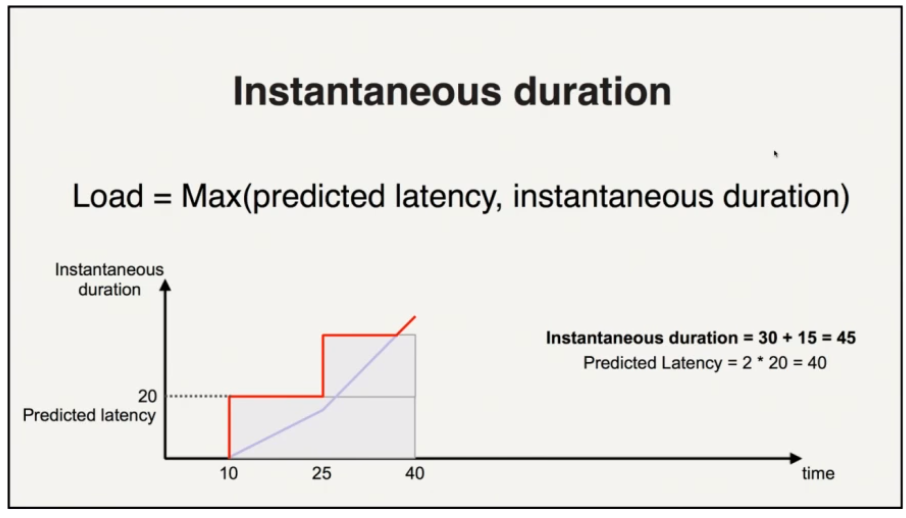
处理突发事件(GC 暂停、网络分区)时效果很好
需要平均一个中位延迟来检测死机/无响应的服务器
不完美
- 延迟并不总是一个完美的信号
- 冷服务器的缓慢预热
- 由于衰变,冷服务器会不时被访问
- 尽管如此,他们在一段时间内的流量会相对较少
- 伪装成成功的错误混淆了系统
- 请求分布可能暂时不均匀